YaRN (Yet another RoPE extensioN) 技术文档
适用对象: AI 研究员、大型模型工程师、深度学习开发者 核心功能: 高效扩展基于 RoPE 的 Transformer 模型的上下文窗口(Context Window)。
1. 简介 (Introduction)
YaRN (Yet another RoPE extensioN) 是一种处于当前最前沿(State-of-the-Art)的位置编码�插值技术,旨在解决基于 RoPE (Rotary Positional Embedding) 的大型语言模型(如 Llama 2/3, Mistral, DeepSeek 等)在处理超过其预训练长度的文本时遇到的"外推(Extrapolation)"困难问题。
简而言之,YaRN 可以让一个原本只能读 4k 长度的模型,在几乎不损失短文本性能的前提下,通过极少量的微调(甚至在某些情况下无需微调),能够高效地处理 32k、64k 甚至 128k 的超长上下文。
核心优势
- 高效性 (Data Efficiency): 相比重新预训练,YaRN 只需要极少量的长文本数据进行微调(SFT)即可达到极佳效果。
- 无损短文本 (Preserves Short-Context): 解决了以往插值方法(如线性插值)导致的短文本性能下降问题。
- 无推理开销 (No Inference Overhead): YaRN 的计算仅在初始化或缓存更新时进行,推理阶段与标准 RoPE 完全一致,不增加延迟或显存占用。
- 广泛适用 (Versatility): 适用于绝大多数使用 RoPE 的现代 LLM 架构。
2. 背景与挑战 (Background & Challenge)
2.1. RoPE 的局限性
现代 LLM 普遍采用旋转位置编码 (RoPE)。RoPE 通过将 token 的 query 和 key 向量在复平面上旋转一定的角度来注入位置信息。这个旋转角度取决于 token 的位置索引 和维度特定的频率 。
在预训练阶段,模型只见过有限范围内的位置索引(例如 到 )。当推理时输入的位置索引 时,旋转角度超出了模型训练时的分布范围,导致注意力机制失效,模型开始"胡言乱语"。
2.2. 早期解决方案的缺陷
为了解决这个问题,研究者们提出了"插值(Interpolation)"方法,即把新的、更长的位置索引"压缩"回模型熟悉的旧范围内。
线性插值 (Linear Scaling):
最简单的方法。如果想扩展 4 倍长度,就将所有输入位置索引除以 4。
- 缺陷: 这相当于把"刻��度尺"均匀拉长了。导致高频部分(负责捕捉局部依赖,如相邻词关系)的信息变得稀疏和模糊。模型变成了"近视眼",短文本性能严重下降。
NTK-Aware:
一种非线性的插值方法。它试图通过改变 RoPE 的基数 (Base) 来在不同频率间分配插值压力。
- 缺陷: 虽然比线性插值好,但仍然无法完美平衡高频和低频信息的保留,尤其是在极大扩展倍数下。
3. YaRN 核心机制 (Core Mechanism)
YaRN 的成功在于它深刻理解了 RoPE 中不同频率维度的作用,并采取了**"分而治之" (Divide and Conquer)** 的策略,辅以注意力温度修正。
3.1. 关键洞察:高频与低频分离
RoPE 的不同维度具有不同的旋转频率:
- 低维度(高频): 旋转速度极快。它们负责捕捉局部的、短距离的 token 依赖关系。这些信息对位置非常敏感,不应该被拉伸(插值)。
- 高维度(低频): 旋转速度极慢。它们负责捕捉全局的、长距离的语义关系。这些信息是需要被拉伸以覆盖更长上下文的。
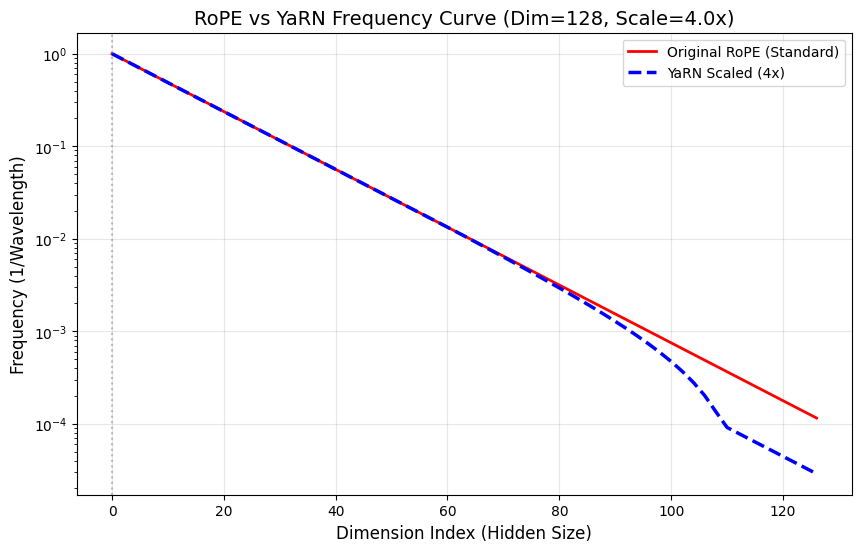
3.2. 混合插值策略 (The "Ramp" Function)
YaRN 引入了一个平滑的"斜坡函数 (Ramp Function)",根据每个维度的波长(频率的倒数)来决定该维度应用哪种策略:
- 高频区 (不插值): 对于波长很短的维度,YaRN 完全不改变其频率,保持原始 RoPE 的行为。这完美保护了短文本性能。
- 低频区 (线性插值): 对于波长很长的维度,YaRN 应用线性插值(将频率除以扩展倍数 ),强制拉长其感知范围。
- 过渡区 (混合): 在两者之间,YaRN 对原始频率和插值频率进行平滑的加权平均。
3.3. 注意力温度修正 (Temperature Scaling / mscale)
当上下文窗口被拉长时,注意力机制中的 Query 和 Key 的点积()的分布会发生变化,导致 Softmax 后的注意力分布变得"平坦(散漫)",模型难以聚焦关键信息(称为"注意力发散")。
YaRN 引入了一个温度系数 mscale(通常 ),乘在注意�力分数上(或直接乘在 RoPE 的 cos/sin 上),人为地放大点积结果,使 Softmax 的分布重新变得尖锐,帮助模型在长噪声中聚焦。
总结公式:
并伴随 的幅度修正。
4. 实现指南 (Implementation Guide)
以下是基于 PyTorch 的 YaRN RoPE 模块的参考实现。你可以用它替换模型中原有的 RotaryPositionalEmbedding 类。
4.1. PyTorch 代码实现
import torch
import torch.nn as nn
import math
class YaRNScaledRotaryEmbedding(nn.Module):
"""
YaRN (Yet another RoPE extensioN) 实现。
替代标准的 RotaryPositionalEmbedding 以支持长上下文。
"""
def __init__(self, dim, max_position_embeddings=2048, base=10000, scale=1.0, original_max_position_embeddings=2048, beta_fast=32, beta_slow=1, device=None):
super().__init__()
self.dim = dim
self.max_position_embeddings = max_position_embeddings # 当前需要支持的最大长度 (例如 32k)
self.base = base
self.scale = scale # 扩展倍数 (例如 32768 / 2048 = 16)
self.original_max_position_embeddings = original_max_position_embeddings # 原始预训练长度 (例如 2048)
# YaRN 的高低频阈值参数 (通常使用默认值即可)
self.beta_fast = beta_fast
self.beta_slow = beta_slow
# 计算并注册缓存
self._compute_inv_freq(device)
# 计算温度缩放系数 mscale
self.mscale = float(0.1 * math.log(scale) + 1.0) if scale > 1 else 1.0
# 初始化缓存占位符
self.max_seq_len_cached = 0
self.register_buffer("cos_cached", None, persistent=False)
self.register_buffer("sin_cached", None, persistent=False)
def _compute_inv_freq(self, device):
# 1. 计算基础频率 (Standard RoPE)
exponent = torch.arange(0, self.dim, 2, device=device).float() / self.dim
inv_freq_base = 1.0 / (self.base ** exponent)
# 如果不扩展,直接使用基础频率
if self.scale <= 1.0:
self.register_buffer("inv_freq", inv_freq_base, persistent=False)
return
# 2. 计算线性插值频率 (Linear Scaling)
inv_freq_linear = inv_freq_base / self.scale
# 3. 计算波长并构建 Ramp 函数
wavelen = 2 * math.pi / inv_freq_base
# ��计算插值比例
ramp = (wavelen / self.original_max_position_embeddings - self.beta_slow) / (self.beta_fast - self.beta_slow)
# 截断到 [0, 1] 区间
ramp = torch.clamp(ramp, 0.0, 1.0)
# 4. 混合频率 (YaRN Core Logic)
# ramp=0 使用原始频率(高频); ramp=1 使用插值频率(低频)
inv_freq_yarn = (1.0 - ramp) * inv_freq_base + ramp * inv_freq_linear
self.register_buffer("inv_freq", inv_freq_yarn, persistent=False)
def _update_cos_sin_cache(self, seq_len, device, dtype):
# 仅当需要时更新缓存
if seq_len > self.max_seq_len_cached:
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
# 计算外积得到角度
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# 拼接形成完整的 emb (对应 sin 和 cos 的两部分)
emb = torch.cat((freqs, freqs), dim=-1)
# 应用 mscale 并计算 cos/sin
self.register_buffer("cos_cached", (emb.cos() * self.mscale).to(dtype), persistent=False)
self.register_buffer("sin_cached", (emb.sin() * self.mscale).to(dtype), persistent=False)
def forward(self, x, seq_len):
# x: [batch, seq_len, n_heads, head_dim]
# 在推理时,传入当前的序列长度以确保缓存足够
if seq_len > self.max_seq_len_cached:
self._update_cos_sin_cache(seq_len, x.device, x.dtype)
# 返回切片后的缓存
return (
self.cos_cached[:seq_len, ...],
self.sin_cached[:seq_len, ...]
)
# --- 辅助函数:应用 RoPE 旋转 ---
def rotate_half(x):
"""Turns x1, x2 into -x2, x1"""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb_yarn(q, k, cos, sin, position_ids=None):
"""
应用 YaRN RoPE 到 q 和 k。
注意:YaRN 的实现通常直接在 cos/sin 上乘了 mscale,所以这里不需要额外处理。
"""
# 确保 cos/sin 的维度与 q/k 匹配以便广播
# 假设 cos/sin 是 [seq_len, dim], q/k 是 [batch, heads, seq_len, dim]
# 需要调整为 [1, 1, seq_len, dim] (根据具体模型实现可能略有不同)
cos = cos.unsqueeze(0).unsqueeze(0)
sin = sin.unsqueeze(0).unsqueeze(0)
# 如果传入了特定的 position_ids (用于推理缓存),则进行gather
if position_ids is not None:
# 这部分逻辑依赖于具体的模型实现,这里仅作示意
pass
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
4.2. 集成步骤
- 定位原 RoPE 模块: 在你的 Transformer 模型代码中找到计算 RoPE
inv_freq和cos/sin缓存的地方。 - 替换初始化: 使用上述
YaRNScaledRotaryEmbedding替换原有的类。确保传入正确的original_max_position_embeddings(原模型训练长度)和scale(你想要扩展的倍数)。 - 替换前向传播: 在 Attention 层的
forward函数中,确保调用新的 YaRN 模块来获取cos和sin,并使用标准的旋转函数应用它们。
5. 配置与最佳实践 (Configuration & Best Practices)
5.1. 参数设置推荐
| 参数名 | 含义 | 推荐值 / 说明 |
|---|---|---|
scale | 扩展倍数 | 目标长度 / 原始长度。例如 4k->32k, scale=8。 |
original_max_position_embeddings | 原始长度 | 必须准确设置。Llama2为4096,MiniMind为512等。 |
max_position_embeddings | 目标长度 | SFT或推理时预期的最大长度。 |
base | RoPE基数 | 通常保持默认 10000 (Llama系列) 或模型特定的值 (如 500000)。 |
beta_fast | 高频阈值 | 默认 32。通常无需更改。 |
beta_slow | 低频阈值 | 默认 1。通常无需更改。 |
5.2. 微调 (Fine-tuning) 建议
虽然 YaRN 理论上可以"免训练"直接推理,但为了获得最佳性能(尤其是困惑度指标),强烈建议进行简短的微调(SFT)。
- 扩展倍数较小 (如 2x - 4x): 可以尝试直接推理,或者用极少量数据微调。
- 扩展倍数较大 (如 > 8x): 必须微调。
- 数据量: 不需要海量数据。通常几百条到几千条高质量的长文本数据(长度达到目标长度)即可。
- 步数: 只需很少的训练步数(例如几百步)模型就能适应新的长度。过度训练可能会损害通用能力。
5.3. 注意力发散问题
在极大扩展倍数(如 128k)下,即使有 YaRN 的 mscale 修正,模型注意力仍可能略显发散。这是正常现象。确保微调数据质量是缓解此问题的关键。
6. 参考文献 (References)
- YaRN 论文: YaRN: Efficient Context Window Extension of Large Language Models (Bowen Peng et al., 2023)
- RoPE 论文: RoFormer: Enhanced Transformer with Rotary Position Embedding (Jianlin Su et al., 2021)
- 相关实现: Llama 2 Long, Mistral AI 的模型均采用了类似 YaRN 的技术。