Transformer 完整架构详解与 PyTorch 实现
这是一份完整的 Transformer 架构代码笔记,整合了从底层的多头注意力(QKV)到中间的编码器/解码器块,再到整体架构和掩码机制的所有核心概念。本文包含极其详尽的中文注释,帮助你深入理解 Transformer 的工作原理。
核心思想回顾:从串行到并行的革命
这段代码复现了 2017 年 Google 论文《Attention Is All You Need》中提出的标准 Transformer 架构。它的核心使命是解决以往 RNN/LSTM 模型无法并行计算且容易遗忘长距离信息的痛点。
Transformer 成功的秘诀在于完全抛弃了循环结构,转而依赖强大的注意力机制 (Attention Mechanism) 来捕捉序列中词与词之间的依赖关系。
架构核心思想
- 抛弃 RNN:使用纯注意力机制,实现并行计算
- 位置编码:弥补没有循环结构导致的位置信息丢失
- 多头注意力:让模型从多个"视角"理解词语间的关联
- Encoder-Decoder 结构:
- Encoder (编码器塔):负责深刻"读懂"源输入,产出"最终笔记"(Memory)
- Decoder (解码器塔):负责"看着笔记写作文",自回归地生成目标输出
代码结构宏观导航:两座独立的"大楼"
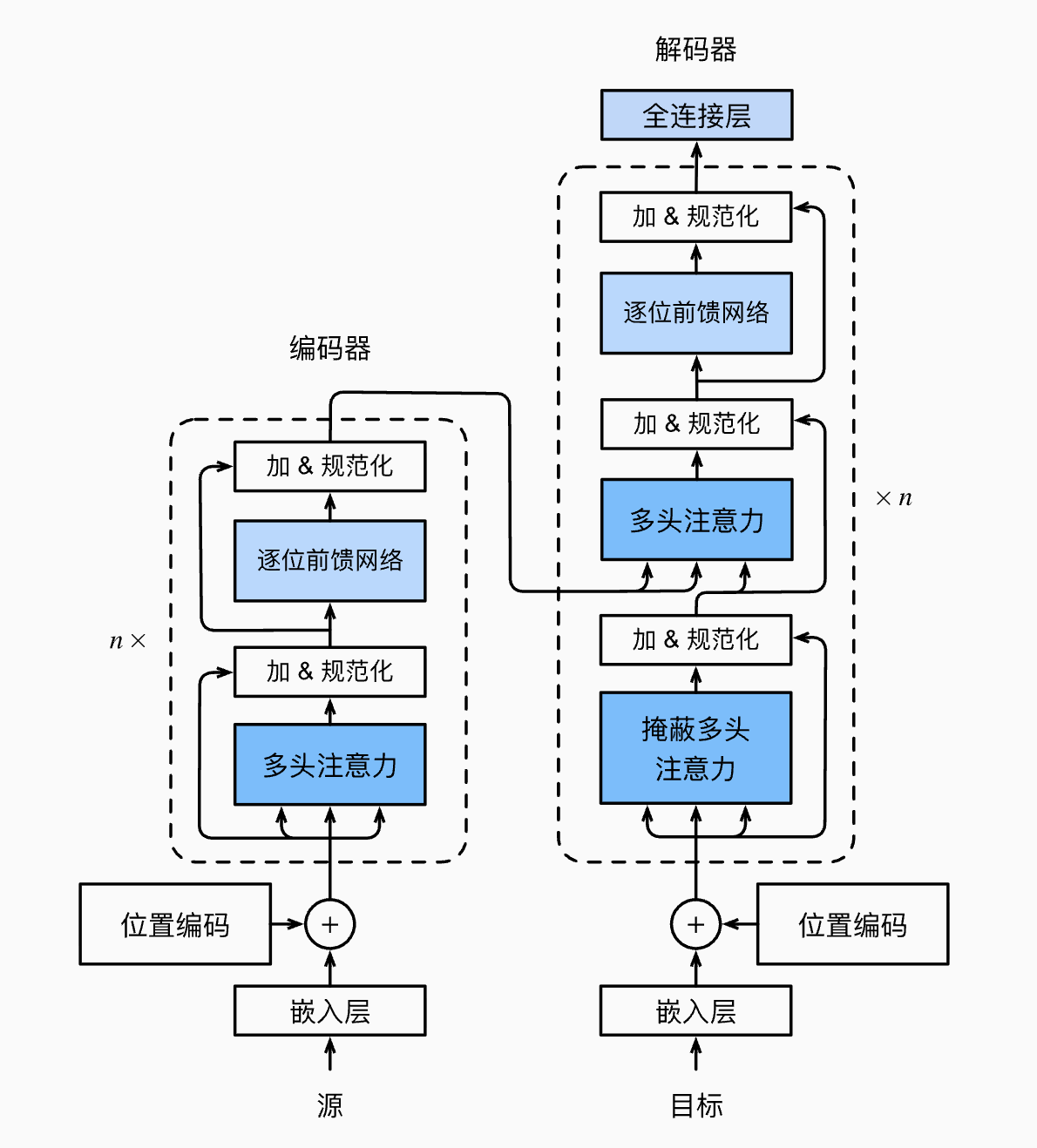
在阅读这份代码时,请务必��牢记:Transformer 并不是编码一层、解码一层交替进行的。它的实际工作流程是**两座独立堆叠的"塔楼"**前后接力完成的:
1. 编码器塔 (Encoder Tower) —— "全知的读书人"
- 任务:负责"读"。并行地接收整个源句子,深刻理解其含义
- 流程:数据从底层的 EncoderLayer 一路向上跑完 N 层
- 产出:最终生成一份包含高度浓缩语义信息的**"最终笔记" (Memory 矩阵)**。这份笔记在接下来的解码阶段保持不变,供解码器反复查阅
- 核心组件:多头自注意力 (Multi-Head Self-Attention),用于建立源句子内部词与词的联系
2. 解码器塔 (Decoder Tower) —— "戴着镣铐的创作者"
- 任务:负责"写"。像打字机一样,自回归地一个字一个字生成目标句子
- 流程:在生成每一个字时,数据都要跑完 N 层解码器
- 两大关键机制:
- "内省" (Masked Self-Attention):查看自己已经写出来的内容。这里必须使用因果掩码 (Causal Mask),防止模型在训练时"偷看未来"的答案
- "查阅" (Cross-Attention):这是连接两座大楼的桥梁。解码器的每一层都会拿着自己的查询 (Q),去查阅编码器提供的那份"最终笔记" (K 和 V),从而确保生成的内容忠实于原文
完整代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class PositionalEncoding(nn.Module):
"""
【模块 1:位置编码 (Positional Encoding)】
作用:因为 Transformer 是并行处理的,它本身不知道词的顺序("我爱你"和"你爱我"对它来说没区别)。
我们需要人为地给每个词的向量里注入位置信息。
"""
def __init__(self, d_model, max_len=5000, dropout=0.1):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 创建一个足够长的矩阵 [max_len, d_model] 来存位置编码
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 论文中的正弦/余弦公式里的分母部分
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 偶数维度用 sin,奇数维度用 cos
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 增加一个 batch 维度: [1, max_len, d_model]
pe = pe.unsqueeze(0)
# register_buffer 表示这个参数不是模型需要训练的权重,但需要随模型保存
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [batch_size, seq_len, d_model] (经过 Embedding 后的输入)
"""
# 【关键操作】直接相加 (Add),而不是拼接。
# 截取和输入序列长度一样长的位置编码加到输入上。
x = x + self.pe[:, :x.size(1), :]
return self.dropout(x)
class MultiHeadAttention(nn.Module):
"""
【模块 2:多头注意力 (Multi-Head Attention) - 核心灵魂】
作用:让输入序列中的每个词都能关注到其他词,计算相关性 (QKV机制)。
"多头"意味着用多个不同的角度去观察(比如一个头看语法,一个头看语义)。
"""
def __init__(self, d_model, num_heads, dropout=0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 每个头处理的维度大小 (例如 512/8 = 64)
# 定义 Q, K, V 的线性投影层 (即训练时要学的权重矩阵 Wq, Wk, Wv)
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
# 最后把所有头拼接起来后的线性层
self.w_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""
实现核心公式: Attention(Q, K, V) = softmax( (Q @ K^T) / sqrt(d_k) ) @ V
"""
# 1. 计算分数 (Scores)
# Q @ K转置。结果 shape: [batch, num_heads, seq_len(q), seq_len(k)]
scores = torch.matmul(Q, K.transpose(-2, -1))
# 2. 缩放 (Scaling) - 防止数值过大导致 Softmax 梯度消失
scores = scores / math.sqrt(self.d_k)
# 3. 掩码 (Masking) - 如果有 mask,把需要忽略的位置填成负无穷
# 这样 Softmax 之后这些位置的概率就是 0
if mask is not None:
# mask 通常是 [batch, 1, seq_len, seq_len]
scores = scores.masked_fill(mask == 0, -1e9)
# 4. 归一化 (Softmax) - 得到注意力权重概率,形状类似于"雨露均沾"的分布
attn_probs = F.softmax(scores, dim=-1)
attn_probs = self.dropout(attn_probs)
# 5. 加权求和 (Weighted Sum) - 得到最终的信息聚合
output = torch.matmul(attn_probs, V)
return output
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# 1. 线性投影:输入 x 乘以 Wq, Wk, Wv
Q = self.w_q(q)
K = self.w_k(k)
V = self.w_v(v)
# 2. 分头 (Split Heads)
# 维度变换: [batch, seq_len, d_model] -> [batch, seq_len, num_heads, d_k]
# 然后转置以便后续计算: -> [batch, num_heads, seq_len, d_k]
Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 3. 计算注意力
output = self.scaled_dot_product_attention(Q, K, V, mask)
# 4. 拼接头 (Concat Heads)
# 把 num_heads 和 d_k 维度并回去 -> [batch, seq_len, d_model]
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 5. 最后的线性变换
output = self.w_o(output)
return output
class FeedForward(nn.Module):
"""
【模块 3:前馈神经网络 (FFN)】
作用:在每个注意力层之后,增加非线性能力,整合信息。
结构是一个瓶颈结构:宽 -> 窄 -> 宽 (例如 512 -> 2048 -> 512)
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(FeedForward, self).__init__()
# 第一层线性层,把维度扩大 (比如 4倍)
self.linear1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
# 第二层线性层,把维度缩回原样
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
# x -> Linear1 -> ReLU -> Dropout -> Linear2
x = self.dropout(F.relu(self.linear1(x)))
x = self.linear2(x)
return x
class EncoderLayer(nn.Module):
"""
【模块 4:编码器块 (Encoder Layer)】
Transformer 大楼里的标准砖块。
包含:Self-Attention + FFN + 残差连接(Add) + 层归一化(Norm)
此处实现的是原始论文的 Post-LN 结构 (先残差,后归一化)。
"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
# --- 子层 1: 多头自注意力 ---
# Q, K, V 都是 x 自己,所以叫 Self-Attention
attn_output = self.self_attn(q=x, k=x, v=x, mask=mask)
# Add & Norm
x = self.norm1(x + self.dropout1(attn_output))
# --- 子层 2:前馈网络 ---
ffn_output = self.ffn(x)
# Add & Norm
x = self.norm2(x + self.dropout2(ffn_output))
return x
class DecoderLayer(nn.Module):
"""
【模块 5:解码器块 (Decoder Layer)】
比编码器更复杂,有三个子层。
关键区别在于多了 Mask 和 Cross-Attention。
"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
# 1. Masked Self-Attention (带掩码的自注意力,防止偷看未来)
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
# 2. Cross-Attention (交叉注意力,看编码器的输出)
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
# 3. FFN
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, memory, tgt_mask=None, src_mask=None):
"""
memory: 编码器塔最终输出的"笔记"
tgt_mask: 因果掩码(Causal Mask),遮住未来
src_mask: 源数据的 Padding Mask,遮住无用的填充符
"""
# --- 子层 1: Masked Self-Attention (内省) ---
# 重点:传入 tgt_mask,确保生成第 i 个词时只能看到 1 到 i-1 的词
attn_output = self.self_attn(q=x, k=x, v=x, mask=tgt_mask)
x = self.norm1(x + self.dropout1(attn_output))
# --- 子层 2: Cross-Attention (查笔记) ---
# 重点:Q 来自解码器自己 (x),K 和 V 来自编码器的笔记 (memory)
# 这里使用的是 src_mask,防止关注到编码器输入里的 padding
attn_output = self.cross_attn(q=x, k=memory, v=memory, mask=src_mask)
x = self.norm2(x + self.dropout2(attn_output))
# --- 子层 3: FFN (推理) ---
ffn_output = self.ffn(x)
x = self.norm3(x + self.dropout3(ffn_output))
return x
class Transformer(nn.Module):
"""
【模块 6:完整的 Transformer 架构】
将上面的组件组装成两座大楼:Encoder Tower 和 Decoder Tower。
"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, num_heads=8,
num_encoder_layers=6, num_decoder_layers=6, d_ff=2048, max_len=5000, dropout=0.1):
super(Transformer, self).__init__()
self.d_model = d_model
# --- 1. Embedding 层 (地基) ---
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model, max_len, dropout)
# --- 2. Encoder 塔堆叠 ---
# 使用 nn.ModuleList 来存储 N 个编码器层
self.encoder_layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_encoder_layers)
])
# 编码器最后的归一化层 (有些实现会加)
self.encoder_norm = nn.LayerNorm(d_model)
# --- 3. Decoder 塔堆叠 ---
# 使用 nn.ModuleList 来存储 N 个解码器层
self.decoder_layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_decoder_layers)
])
self.decoder_norm = nn.LayerNorm(d_model)
# --- 4. 输出头 (天台) ---
# 将向量映射回目标语言词表大小,用于计算概率
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
# 初始化参数 (Trick: 有助于模型收敛)
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def encode(self, src, src_mask):
"""编码器塔的前向传播流程"""
# 1. Embedding + 缩放 + 位置编码
# 乘以 sqrt(d_model) 是为了平衡 embedding 和位置编码的数值量级
src = self.src_embedding(src) * math.sqrt(self.d_model)
src = self.pos_encoder(src)
# 2. 一层一层向上跑
for layer in self.encoder_layers:
src = layer(src, src_mask)
# 3. 最终归一化,得到"最终笔记" Memory
return self.encoder_norm(src)
def decode(self, tgt, memory, tgt_mask, src_mask):
"""解码器塔的前向传播流程"""
# 1. Embedding + 缩放 + 位置编码
tgt = self.tgt_embedding(tgt) * math.sqrt(self.d_model)
tgt = self.pos_encoder(tgt)
# 2. 一层一层向上跑
for layer in self.decoder_layers:
# 注意:每一层都接收同样的 memory 和 mask
tgt = layer(tgt, memory, tgt_mask, src_mask)
return self.decoder_norm(tgt)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
"""
整个模型的前向传播。
注意流程:先完整运行编码器,再运行解码器。
"""
# 阶段 1:全体编码器集合!产出笔记
memory = self.encode(src, src_mask)
# 阶段 2:全体解码器集合!参考笔记进行生成
decoder_output = self.decode(tgt, memory, tgt_mask, src_mask)
# 阶段 3:输出层映射得到 Logits
output = self.fc_out(decoder_output)
return output
# =============================================================================
# 【工具函数:生成掩码 (Masks)】
# =============================================================================
def generate_square_subsequent_mask(sz):
"""
生成因果掩码 (Causal Mask / Look-ahead Mask)。
用于解码器的 Self-Attention,防止看到未来的词。
生成一个上三角矩阵 (不含对角线),填充为负无穷。
"""
mask = torch.triu(torch.ones(sz, sz), diagonal=1)
mask = mask.masked_fill(mask == 1, float('-inf'))
return mask
def create_padding_mask(seq, pad_idx):
"""
生成 Padding Mask。
用于告诉 Attention 机制忽略掉输入序列中的填充符 (Pad Token)。
返回形状: [batch_size, 1, 1, seq_len] 以便广播到多头注意力中
"""
# seq shape: [batch_size, seq_len]
# mask shape: [batch_size, seq_len] -> True 表示是 padding
mask = (seq == pad_idx)
# 扩展维度以便后续计算
return mask.unsqueeze(1).unsqueeze(2)
运行示例
# 1. 定义超参数
src_vocab_size = 1000 # 源语言词表大小
tgt_vocab_size = 2000 # 目标语言词表大小
d_model = 512 # 词向量维度
num_heads = 8 # 注意力头数
num_layers = 3 # 编码器和解码器的层数 (为了演示用3层,原来是6)
d_ff = 2048 # FFN 中间层维度
max_len = 100 # 最大句子长度
pad_idx = 0 # 填充符的索引 ID
# 2. 实例化模型
model = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads,
num_layers, num_layers, d_ff, max_len)
print("模型结构已创建成功!")
# 3. 创建模拟输入数据 (Batch size = 2)
# 源句子 (比��如英文): 长度不一样,短的用 0 (pad_idx) 填充
src_seq = torch.LongTensor([
[10, 20, 30, 40, 0, 0], # 句子 1长度 4
[15, 25, 35, 45, 55, 0] # 句子 2长度 5
])
# 目标句子输入 (比如中文): 解码器的输入,通常以 <SOS> 开头,不包含 <EOS>
# 假设 1 是 <SOS>
tgt_seq_input = torch.LongTensor([
[1, 100, 200, 300, 0],
[1, 150, 250, 350, 450]
])
# 4. 创建必要的掩码
# (A) 源数据 Padding Mask: 告诉编码器不要关注 0
src_mask = create_padding_mask(src_seq, pad_idx)
# (B) 目标数据 Padding Mask: 告诉解码器不要关注 0
tgt_pad_mask = create_padding_mask(tgt_seq_input, pad_idx)
# (C) 目标数据因果掩码: 告诉解码器不要偷看未来
tgt_len = tgt_seq_input.size(1)
tgt_causal_mask = generate_square_subsequent_mask(tgt_len)
# 合并解码器的两个掩码
tgt_mask = tgt_causal_mask
print(f"\n源输入形状: {src_seq.shape}")
print(f"目标输入形状: {tgt_seq_input.shape}")
print(f"因果掩码形状: {tgt_mask.shape}")
# 5. 模型前向传播
output = model(src_seq, tgt_seq_input, src_mask=src_mask, tgt_mask=tgt_mask)
# 6. 查看输出
print(f"\n模型输出形状 (Logits): {output.shape}")
print("预期形状解释: [Batch Size, Target Seq Len, Target Vocab Size]")
# 输出应该是 [2, 5, 2000],表示对 batch 中 2 个句子,每个句子的 5 个位置,预测 2000 个词的概率分数。
print("\n演示结束。这段代码完整展示了 Transformer 的内部计算流程。")
核心公式
Transformer 中的核心注意力机制公式为:
其中:
- (Query): 查询矩阵
- (Key): 键矩阵
- (Value): 值矩阵
- : 键向量的维度
- : 缩放因子,防止内积过大导致梯度消失
代码阅读指南
这份笔记的代码实现遵循了自底向上的构建方式:
- 先实现最基础的零件:
PositionalEncoding(位置编码) 和MultiHeadAttention(多头注意力) - 再组装成标准的楼层:
EncoderLayer和DecoderLayer - 最后在主类
Transformer中:将这些楼层堆叠成两座大楼,并定义了完整的前向传播逻辑
关键要点总结
- 位置编码:使用正弦/余弦函数为每个位置生成唯一的编码,通过相加的方式注入到词向量中
- 多头注意力:将注意力机制分成多个头,每个头关注不同的语义子空间
- 编码器-解码器分离:编码器完整运行产出 Memory,解码器利用 Memory 逐步生成输出
- 掩码机制:
- Padding Mask:忽略填充符号
- Causal Mask:防止解码器看到未来信息
- 残差连接与层归一化:帮助深层网络训练,缓解梯度消失问题
参考资料
- 原始论文:Attention Is All You Need (Vaswani et al., 2017)
- The Illustrated Transformer
- PyTorch 官方 Transformer 教程